Running Timefold Solver
1. The Solver interface
A Solver solves your planning problem.
-
Java
-
Python
public interface Solver<Solution_> {
Solution_ solve(Solution_ problem);
...
}class Solver(Generic[Solution_]):
...
def solve(self, problem: Solution_) -> Solution_:
...A Solver can only solve one planning problem instance at a time.
It is built with a SolverFactory, there is no need to implement it yourself.
A Solver should only be accessed from a single thread, except for the methods that are specifically documented in javadoc as being thread-safe.
The solve() method hogs the current thread.
This can cause HTTP timeouts for REST services and it requires extra code to solve multiple datasets in parallel.
To avoid such issues, use a SolverManager instead.
2. Solving a problem
Solving a problem is quite easy once you have:
-
A
Solverbuilt from a solver configuration -
A
@PlanningSolutionthat represents the planning problem instance
Just provide the planning problem as argument to the solve() method and it will return the best solution found:
-
Java
-
Python
Timetable problem = ...;
Timetable bestSolution = solver.solve(problem);problem = Timetable(...)
best_solution = solver.solve(problem)In school timetabling,
the solve() method will return a Timetable instance with every Lesson assigned to a Teacher and a Timeslot.
The solve(Solution) method can take a long time (depending on the problem size and the solver configuration).
The Solver intelligently wades through the search space of possible solutions
and remembers the best solution it encounters during solving.
Depending on a number of factors (including problem size, how much time the Solver has, the solver configuration, …),
that best solution might or might not be an optimal solution.
|
The solution instance given to the method The solution instance returned by the methods |
|
The solution instance given to the |
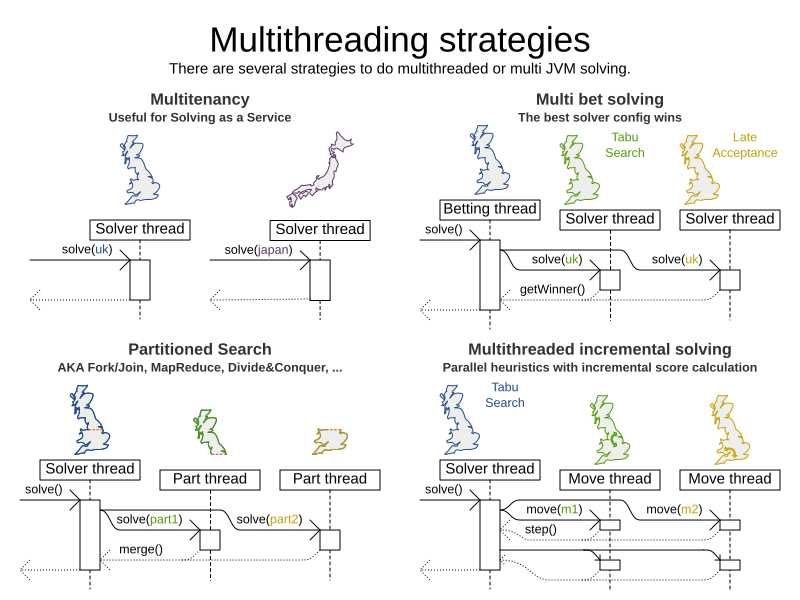
2.1. Multi-threaded solving
There are several ways of running the solver in parallel:
-
Multi-threaded incremental solving: Solve 1 dataset with multiple threads without sacrificing incremental score calculation. This is an exclusive feature of the Enterprise Edition.
-
Partitioned search: Split 1 dataset in multiple parts and solve them independently. This is an exclusive feature of the Enterprise Edition.
-
Multi bet solving: solve 1 dataset with multiple, isolated solvers and take the best result.
-
Not recommended: This is a marginal gain for a high cost of hardware resources.
-
Use the Benchmarker during development to determine the algorithm that is the most appropriate on average.
-
-
Multitenancy: solve different datasets in parallel.
-
The
SolverManagercan help with this.
-
3. Environment mode: are there bugs in my code?
The environment mode allows you to detect common bugs in your implementation. It does not affect the logging level.
You can set the environment mode in the solver configuration XML file:
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
<environmentMode>FAST_ASSERT</environmentMode>
...
</solver>A solver has a single Random instance.
Some solver configurations use the Random instance a lot more than others.
For example, Simulated Annealing depends highly on random numbers, while Tabu Search only depends on it to deal with score ties.
The environment mode influences the seed of that Random instance.
These are the environment modes:
3.1. FULL_ASSERT
The FULL_ASSERT mode turns on all assertions (such as assert that the incremental score calculation is uncorrupted for each move) to fail-fast on a bug in a Move implementation, a constraint, the engine itself, …
This mode is reproducible.
It is also intrusive because it calls the method calculateScore() more frequently than a non-assert mode.
The FULL_ASSERT mode is horribly slow,
because it does not rely on incremental score calculation.
3.2. TRACKED_FULL_ASSERT
The TRACKED_FULL_ASSERT mode turns on all the FULL_ASSERT assertions
and additionally tracks changes to the working solution.
This allows the solver to report exactly what variables were corrupted and what variable listener events are missing.
In particular, the solver will recalculate all shadow variables from scratch on the solution after the undo and then report:
-
Genuine and shadow variables that are different between "before" and "undo". After an undo move is evaluated, it is expected to exactly match the original working solution.
-
Variables that are different between "from scratch" and "before". This is to detect if the solution was corrupted before the move was evaluated due to shadow variable corruption.
-
Variables that are different between "from scratch" and "undo". This is to detect if recalculating the shadow variables from scratch is different from the incremental shadow variable calculation.
-
Missing variable listener events for the actual move. Any variable that changed between the "before move" solution and the "after move" solution without either a
beforeVariableChangedorafterVariableChangedwould be reported here. -
Missing variable listener events for undo move. Any variable that changed between the "after move" solution and "after undo move" solution without either a
beforeVariableChangedorafterVariableChangedwould be reported here.
This mode is reproducible (see the reproducible mode).
It is also intrusive because it calls the method calculateScore() more frequently than a non-assert mode.
The TRACKED_FULL_ASSERT mode is by far the slowest mode,
because it clones solutions before and after each move.
3.3. NON_INTRUSIVE_FULL_ASSERT
The NON_INTRUSIVE_FULL_ASSERT turns on several assertions to fail-fast on a bug in a Move implementation,
a constraint, the engine itself, …
This mode is reproducible.
It is non-intrusive because it does not call the method calculateScore() more frequently than a non assert mode.
The NON_INTRUSIVE_FULL_ASSERT mode is horribly slow,
because it does not rely on incremental score calculation.
3.4. FAST_ASSERT
The FAST_ASSERT mode turns on most assertions (such as assert that an undoMove’s score is the same as before the Move)
to fail-fast on a bug in a Move implementation, a constraint, the engine itself, …
This mode is reproducible.
It is also intrusive because it calls the method calculateScore() more frequently than a non-assert mode.
The FAST_ASSERT mode is slow.
It is recommended to write a test case that does a short run of your planning problem with the FAST_ASSERT mode on.
3.5. REPRODUCIBLE (default)
The reproducible mode is the default mode because it is recommended during development. In this mode, two runs in the same Timefold Solver version will execute the same code in the same order. Those two runs will have the same result at every step, except if the note below applies. This enables you to reproduce bugs consistently. It also allows you to benchmark certain refactorings (such as a score constraint performance optimization) fairly across runs.
|
Despite the reproducible mode, your application might still not be fully reproducible because of:
|
The reproducible mode can be slightly slower than the non-reproducible mode. If your production environment can benefit from reproducibility, use this mode in production.
In practice, this mode uses the default, fixed random seed if no seed is specified, and it also disables certain concurrency optimizations, such as work stealing.
3.6. NON_REPRODUCIBLE
The non-reproducible mode can be slightly faster than the reproducible mode. Avoid using it during development as it makes debugging and bug fixing painful. If your production environment doesn’t care about reproducibility, use this mode in production.
In practice, this mode uses no fixed random seed if no seed is specified.
4. Logging level: what is the Solver doing?
The best way to illuminate the black box that is a Solver, is to play with the logging level:
-
error: Log errors, except those that are thrown to the calling code as a
RuntimeException.If an error happens, Timefold Solver normally fails fast: it throws a subclass of
RuntimeExceptionwith a detailed message to the calling code. It does not log it as an error itself to avoid duplicate log messages. Except if the calling code explicitly catches and eats thatRuntimeException, aThread's defaultExceptionHandlerwill log it as an error anyway. Meanwhile, the code is disrupted from doing further harm or obfuscating the error. -
warn: Log suspicious circumstances.
-
info: Log every phase and the solver itself. See scope overview.
-
debug: Log every step of every phase. See scope overview.
-
trace: Log every move of every step of every phase. See scope overview.
|
Turning on Even Both trace logging and debug logging cause congestion in multi-threaded solving with most appenders, see below. In Eclipse, |
For example, set it to debug logging, to see when the phases end and how fast steps are taken:
INFO Solving started: time spent (31), best score (-8init/0hard/0soft), environment mode (REPRODUCIBLE), move thread count (NONE), random (JDK with seed 0).
INFO Problem scale: entity count (4), variable count (8), approximate value count (4), approximate problem scale (256).
DEBUG CH step (0), time spent (47), score (-6init/0hard/0soft), selected move count (4), picked move ([Math(0) {null -> Room A}, Math(0) {null -> MONDAY 08:30}]).
DEBUG CH step (1), time spent (50), score (-4init/0hard/0soft), selected move count (4), picked move ([Physics(1) {null -> Room A}, Physics(1) {null -> MONDAY 09:30}]).
DEBUG CH step (2), time spent (51), score (-2init/-1hard/-1soft), selected move count (4), picked move ([Chemistry(2) {null -> Room B}, Chemistry(2) {null -> MONDAY 08:30}]).
DEBUG CH step (3), time spent (52), score (-2hard/-1soft), selected move count (4), picked move ([Biology(3) {null -> Room A}, Biology(3) {null -> MONDAY 08:30}]).
INFO Construction Heuristic phase (0) ended: time spent (53), best score (-2hard/-1soft), move evaluation speed (1066/sec), step total (4).
DEBUG LS step (0), time spent (56), score (-2hard/0soft), new best score (-2hard/0soft), accepted/selected move count (1/1), picked move (Chemistry(2) {Room B, MONDAY 08:30} <-> Physics(1) {Room A, MONDAY 09:30}).
DEBUG LS step (1), time spent (60), score (-2hard/1soft), new best score (-2hard/1soft), accepted/selected move count (1/2), picked move (Math(0) {Room A, MONDAY 08:30} <-> Physics(1) {Room B, MONDAY 08:30}).
DEBUG LS step (2), time spent (60), score (-2hard/0soft), best score (-2hard/1soft), accepted/selected move count (1/1), picked move (Math(0) {Room B, MONDAY 08:30} <-> Physics(1) {Room A, MONDAY 08:30}).
...
INFO Local Search phase (1) ended: time spent (100), best score (0hard/1soft), move evaluation speed (2021/sec), step total (59).
INFO Solving ended: time spent (100), best score (0hard/1soft), move evaluation speed (1100/sec), phase total (2), environment mode (REPRODUCIBLE), move thread count (NONE).All time spent values are in milliseconds.
-
Java
-
Python
Everything is logged to SLF4J, which is a simple logging facade which delegates every log message to Logback, Apache Commons Logging, Log4j or java.util.logging. Add a dependency to the logging adaptor for your logging framework of choice.
If you are not using any logging framework yet, use Logback by adding this Maven dependency (there is no need to add an extra bridge dependency):
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.x</version>
</dependency>Configure the logging level on the ai.timefold.solver package in your logback.xml file:
<configuration>
<logger name="ai.timefold.solver" level="debug"/>
...
</configuration>If it isn’t picked up, temporarily add the system property -Dlogback.debug=true to figure out why.
Everything is logged to the timefold.solver logger in Python’s builtin logging module.
Configure the logging level on the timefold.solver logger in a logging.conf file:
[loggers]
keys=root,timefold_solver
[handlers]
keys=consoleHandler
[formatters]
keys=simpleFormatter
[logger_root]
level=INFO
handlers=consoleHandler
[logger_timefold_solver]
level=INFO
qualname=timefold.solver
handlers=consoleHandler
propagate=0
[handler_consoleHandler]
class=StreamHandler
level=INFO
formatter=simpleFormatter
[formatter_simpleFormatter]
format=%(asctime)s - %(name)s - %(levelname)s - %(message)sThen load the logging configuration in Python:
import logging
import logging.config
logging.config.fileConfig('logging.conf')|
When running multiple solvers or a multi-threaded solver,
most appenders (including the console) cause congestion with |
|
In a multitenant application, multiple Then configure your logger to use different files for each |
5. Monitoring the solver
|
This feature is currently not supported in Timefold Solver for Python. |
Timefold Solver exposes metrics through Micrometer which you can use to monitor the solver. Timefold automatically connects to configured registries when it is used in Quarkus or Spring Boot. If you use Timefold with plain Java, you must add the metrics registry to the global registry.
-
You have a plain Java Timefold Solver project.
-
You have configured a Micrometer registry. For information about configuring Micrometer registries, see the Micrometer web site.
-
Add configuration information for the Micrometer registry for your desired monitoring system to the global registry.
-
Add the following line below the configuration information, where
<REGISTRY>is the name of the registry that you configured:Metrics.addRegistry(<REGISTRY>);The following example shows how to add the Prometheus registry:
PrometheusMeterRegistry prometheusRegistry = new PrometheusMeterRegistry(PrometheusConfig.DEFAULT); try { HttpServer server = HttpServer.create(new InetSocketAddress(8080), 0); server.createContext("/prometheus", httpExchange -> { String response = prometheusRegistry.scrape(); (1) httpExchange.sendResponseHeaders(200, response.getBytes().length); try (OutputStream os = httpExchange.getResponseBody()) { os.write(response.getBytes()); } }); new Thread(server::start).start(); } catch (IOException e) { throw new RuntimeException(e); } Metrics.addRegistry(prometheusRegistry); -
Open your monitoring system to view the metrics for your Timefold Solver project. The following metrics are exposed:
The names and format of the metrics vary depending on the registry.
-
timefold.solver.errors.total: the total number of errors that occurred while solving since the start of the measuring. -
timefold.solver.solve.duration.active-count: the number of solvers currently solving. -
timefold.solver.solve.duration.seconds-max: run time of the longest-running currently active solver. -
timefold.solver.solve.duration.seconds-duration-sum: the sum of each active solver’s solve duration. For example, if there are two active solvers, one running for three minutes and the other for one minute, the total solve time is four minutes.
-
5.1. Additional metrics
For more detailed monitoring, Timefold Solver can be configured to monitor additional metrics at a performance cost.
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
<monitoring>
<metric>BEST_SCORE</metric>
<metric>SCORE_CALCULATION_COUNT</metric>
...
</monitoring>
...
</solver>The following metrics are available:
-
SOLVE_DURATION(default, Micrometer meter id: "timefold.solver.solve.duration"): Measurse the duration of solving for the longest active solver, the number of active solvers and the cumulative duration of all active solvers. -
ERROR_COUNT(default, Micrometer meter id: "timefold.solver.errors"): Measures the number of errors that occur while solving. -
SCORE_CALCULATION_COUNT(default, Micrometer meter id: "timefold.solver.score.calculation.count"): Measures the number of score calculations Timefold Solver performed. -
MOVE_EVALUATION_COUNT(default, Micrometer meter id: "timefold.solver.move.evaluation.count"): Measures the number of move evaluations Timefold Solver performed. -
PROBLEM_ENTITY_COUNT(default, Micrometer meter id: "timefold.solver.problem.entities"): Measures the number of entities in the problem submitted to Timefold Solver. -
PROBLEM_VARIABLE_COUNT(default, Micrometer meter id: "timefold.solver.problem.variables"): Measures the number of genuine variables in the problem submitted to Timefold Solver. -
PROBLEM_VALUE_COUNT(default, Micrometer meter id: "timefold.solver.problem.values"): Measures the approximate number of planning values in the problem submitted to Timefold Solver. -
PROBLEM_SIZE_LOG(default, Micrometer meter id: "timefold.solver.problem.size.log"): Measures the approximate log 10 of the search space size for the problem submitted to Timefold Solver. -
BEST_SCORE(Micrometer meter id: "timefold.solver.best.score.*"): Measures the score of the best solution Timefold Solver found so far. There are separate meters for each level of the score. For instance, for aHardSoftScore, there aretimefold.solver.best.score.hard.scoreandtimefold.solver.best.score.soft.scoremeters. -
STEP_SCORE(Micrometer meter id: "timefold.solver.step.score.*"): Measures the score of each step Timefold Solver takes. There are separate meters for each level of the score. For instance, for aHardSoftScore, there aretimefold.solver.step.score.hard.scoreandtimefold.solver.step.score.soft.scoremeters. -
BEST_SOLUTION_MUTATION(Micrometer meter id: "timefold.solver.best.solution.mutation"): Measures the number of changed planning variables between consecutive best solutions. -
MOVE_COUNT_PER_STEP(Micrometer meter id: "timefold.solver.step.move.count"): Measures the number of moves evaluated in a step. -
MOVE_COUNT_PER_TYPE(Micrometer meter id: "timefold.solver.move.type.count"): Measures the number of moves evaluated per move type. -
MEMORY_USE(Micrometer meter id: "jvm.memory.used"): Measures the amount of memory used across the JVM. This does not measure the amount of memory used by a solver; two solvers on the same JVM will report the same value for this metric. -
CONSTRAINT_MATCH_TOTAL_BEST_SCORE(Micrometer meter id: "timefold.solver.constraint.match.best.score.*"): Measures the score impact of each constraint on the best solution Timefold Solver found so far. There are separate meters for each level of the score, with tags for each constraint. For instance, for aHardSoftScorefor a constraint "Minimize Cost", there aretimefold.solver.constraint.match.best.score.hard.scoreandtimefold.solver.constraint.match.best.score.soft.scoremeters with a tag "constraint.name=Minimize Cost". -
CONSTRAINT_MATCH_TOTAL_STEP_SCORE(Micrometer meter id: "timefold.solver.constraint.match.step.score.*"): Measures the score impact of each constraint on the current step. There are separate meters for each level of the score, with tags for each constraint. For instance, for aHardSoftScorefor a constraint "Minimize Cost", there aretimefold.solver.constraint.match.step.score.hard.scoreandtimefold.solver.constraint.match.step.score.soft.scoremeters with a tag "constraint.name=Minimize Cost". -
PICKED_MOVE_TYPE_BEST_SCORE_DIFF(Micrometer meter id: "timefold.solver.move.type.best.score.diff.*"): Measures how much a particular move type improves the best solution. There are separate meters for each level of the score, with a tag for the move type. For instance, for aHardSoftScoreand aChangeMovefor the room of a lesson, there aretimefold.solver.move.type.best.score.diff.hard.scoreandtimefold.solver.move.type.best.score.diff.soft.scoremeters with the tagmove.type=ChangeMove(Lesson.room). -
PICKED_MOVE_TYPE_STEP_SCORE_DIFF(Micrometer meter id: "timefold.solver.move.type.step.score.diff.*"): Measures how much a particular move type improves the best solution. There are separate meters for each level of the score, with a tag for the move type. For instance, for aHardSoftScoreand aChangeMovefor the room of a lesson, there aretimefold.solver.move.type.step.score.diff.hard.scoreandtimefold.solver.move.type.step.score.diff.soft.scoremeters with the tagmove.type=ChangeMove(Lesson.room).
6. Random number generator
Many heuristics and metaheuristics depend on a pseudorandom number generator for move selection, to resolve score ties, probability based move acceptance, … During solving, the same Random instance is reused to improve reproducibility, performance and uniform distribution of random values.
To change the random seed of that Random instance, specify a randomSeed:
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
<randomSeed>0</randomSeed>
...
</solver>To change the pseudorandom number generator implementation, specify a randomType:
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
<randomType>MERSENNE_TWISTER</randomType>
...
</solver>The following types are supported:
-
JDK(default): Standard implementation (java.util.Random). -
MERSENNE_TWISTER: Implementation by Commons Math. -
WELL512A,WELL1024A,WELL19937A,WELL19937C,WELL44497AandWELL44497B: Implementation by Commons Math.
For most use cases, the randomType has no significant impact on the average quality of the best solution on multiple datasets. If you want to confirm this on your use case, use the benchmarker.
7. SolverManager
A SolverManager is a facade for one or more Solver instances
to simplify solving planning problems in REST and other enterprise services.
Unlike the Solver.solve(…) method:
-
SolverManager.solve(…)returns immediately: it schedules a problem for asynchronous solving without blocking the calling thread. This avoids timeout issues of HTTP and other technologies. -
SolverManager.solve(…)solves multiple planning problems of the same domain, in parallel.
Internally a SolverManager manages a thread pool of solver threads, which call Solver.solve(…),
and a thread pool of consumer threads, which handle best solution changed events.
In Quarkus and Spring Boot,
the SolverManager instance is automatically injected in your code.
Otherwise, build a SolverManager instance with the create(…) method:
-
Java
-
Python
SolverConfig solverConfig = SolverConfig.createFromXmlResource(".../solverConfig.xml");
SolverManager<VehicleRoutePlan, String> solverManager = SolverManager.create(solverConfig, new SolverManagerConfig());from pathlib import Path
solver_config = SolverConfig.create_from_xml_resource(Path(...) / 'solver_config.xml')
solver_manager = SolverManager.create(solver_config)Each problem submitted to the SolverManager.solve(…) methods needs a unique problem ID.
Later calls to getSolverStatus(problemId) or terminateEarly(problemId) use that problem ID
to distinguish between the planning problems.
The problem ID must be an immutable class, such as Long, String or java.util.UUID.
The SolverManagerConfig class has a parallelSolverCount property,
that controls how many solvers are run in parallel.
For example, if set to 4, submitting five problems
has four problems solving immediately, and the fifth one starts when another one ends.
If those problems solve for 5 minutes each, the fifth problem takes 10 minutes to finish.
By default, parallelSolverCount is set to AUTO, which resolves to half the CPU cores,
regardless of the moveThreadCount of the solvers.
To retrieve the best solution, after solving terminates normally, use SolverJob.getFinalBestSolution():
-
Java
-
Python
VehicleRoutePlan problem1 = ...;
String problemId = UUID.randomUUID().toString();
// Returns immediately
SolverJob<VehicleRoutePlan, String> solverJob = solverManager.solve(problemId, problem1);
...
try {
// Returns only after solving terminates
VehicleRoutePlan solution1 = solverJob.getFinalBestSolution();
} catch (InterruptedException | ExecutionException e) {
throw ...;
}import uuid
problem1 = ...
problem_id = str(uuid.uuid4())
# Returns immediately
solver_job = solver_manager.solve(problem_id, problem1)
...
try:
# Returns only after solving terminates
solution1 = solver_job.get_final_best_solution()
except:
raise ...However, there are better approaches, both for solving batch problems before an end-user needs the solution as well as for live solving while an end-user is actively waiting for the solution, as explained below.
The current SolverManager implementation runs on a single computer node,
but future work aims to distribute solver loads across a cloud.
7.1. Solve batch problems
At night, batch solving is a great approach to deliver solid plans by breakfast, because:
-
There are typically few or no problem changes in the middle of the night. Some organizations even enforce a deadline, for example, submit all day off requests before midnight.
-
The solvers can run for much longer, often hours, because nobody’s waiting for it and CPU resources are often cheaper.
To solve a multiple datasets in parallel (limited by parallelSolverCount),
call solve(…) for each dataset:
-
Java
-
Python
public class TimetableService {
private SolverManager<Timetable, Long> solverManager;
// Returns immediately, call it for every dataset
public void solveBatch(Long timetableId) {
solverManager.solve(timetableId,
// Called once, when solving starts
this::findById,
// Called once, when solving ends
this::save);
}
public Timetable findById(Long timetableId) {...}
public void save(Timetable timetable) {...}
}class TimetableService:
solver_manager: SolverManager[Timetable, int]
# Returns immediately, call it for every dataset
def solve_batch(self, timetable_id: int) -> None:
self.solver_manager.solve(timetable_id,
# Called once, when solving starts
lambda problem_id: self.find_by_id(problem_id),
# Called once, when solving ends
lambda solution: self.save(solution))
def find_by_id(self, timetable_id: int) -> Timetable:
...
def save(self, timetable: Timetable) -> None:
...A solid plan delivered by breakfast is great, even if you need to react on problem changes during the day.
7.2. Solve and listen to show progress to the end-user
When a solver is running while an end-user is waiting for that solution, the user might need to wait for several minutes or hours before receiving a result. To assure the user that everything is going well, show progress by displaying the best solution and best score attained so far.
To handle intermediate best solutions, use solveAndListen(…):
-
Java
-
Python
public class TimetableService {
private SolverManager<Timetable, Long> solverManager;
// Returns immediately
public void solveLive(Long timetableId) {
solverManager.solveAndListen(timetableId,
// Called once, when solving starts
this::findById,
// Called multiple times, for every best solution change
this::save);
}
public Timetable findById(Long timetableId) {...}
public void save(Timetable timetable) {...}
public void stopSolving(Long timetableId) {
solverManager.terminateEarly(timetableId);
}
}class TimetableService:
solver_manager: SolverManager[Timetable, int]
# Returns immediately
def solve_live(self, timetable_id: int) -> None:
self.solver_manager.solve_and_listen(timetable_id,
# Called once, when solving starts
lambda problem_id: self.find_by_id(problem_id),
# Called multiple times, for every best solution change
lambda solution: self.save(solution))
def find_by_id(self, timetable_id: int) -> Timetable:
...
def save(self, timetable: Timetable) -> None:
...
def stop_solving(self, timetable_id: int) -> None:
self.solver_manager.terminate_early(timetable_id)This implementation is using the database to communicate with the UI, which polls the database. More advanced implementations push the best solutions directly to the UI or a messaging queue.
If the user is satisfied with the intermediate best solution
and does not want to wait any longer for a better one, call SolverManager.terminateEarly(problemId).
|
Best solution events may be triggered in a rapid succession, especially at the start of solving. Users of our Enterprise Edition may use the throttling feature to limit the number of best solution events fired over any period of time. Community Edition users may implement their own throttling mechanism within the |